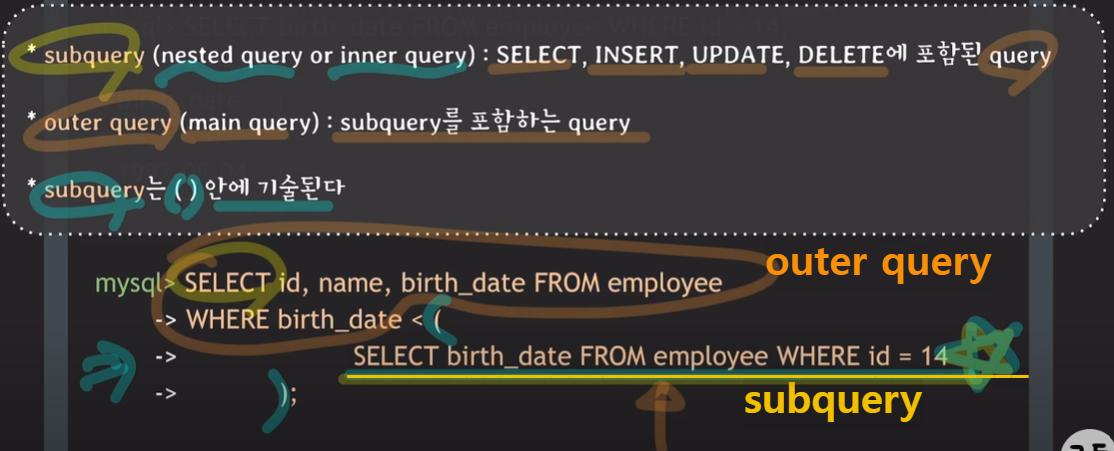
subquery
SELECT with subquery
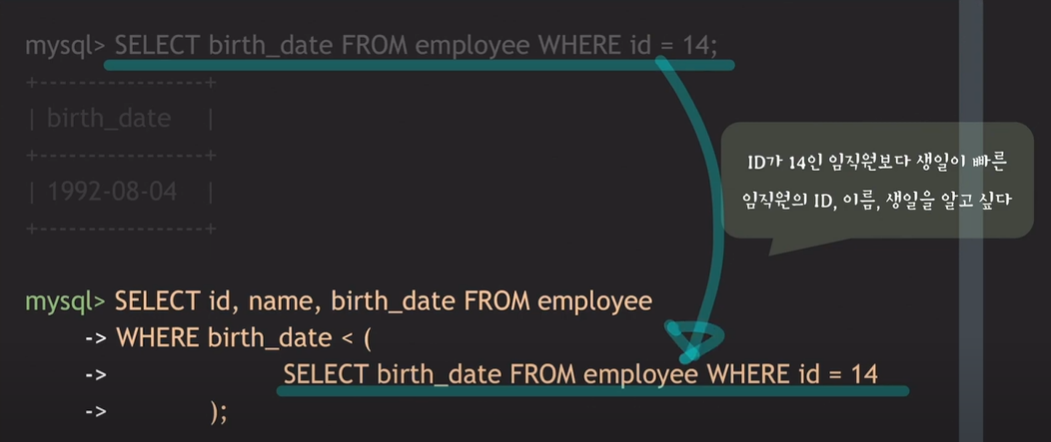
- ID가 14인 임직원보다 생일이 빠른 임직원의 ID, 이름, 생일을 알고 싶음

- 2개의 query를 한번에 실행할 수는 없을까?
- 당연히 가능. 두 번째 query의 조건 부분이 첫 번째 query를 실행했을때 나온 결과이기에
- 즉, 위 그림과 같이 첫 번째 query를 두 번째 query의 조건 부분에 넣으면 됨
<용어 정리>
* subquery (nested query or inner query) : SELECT, INSERT, UPDATE, DELETE에 포함된 query
* outer query(main query) : subquery를 포함하는 query
* subquery는 ( ) 안에 기술된다.
SELECT with subquery
- ID가 1인 임직원과 같은 부서 같은 성별인 임직원들의 ID와 이름과 직군을 알고 싶음

- subquery의 결과가 하나 이상의 attribute를 return할 수 있음
- 그 하나 이상의 attribute와 비교 할 수 있음
SELECT with subquery
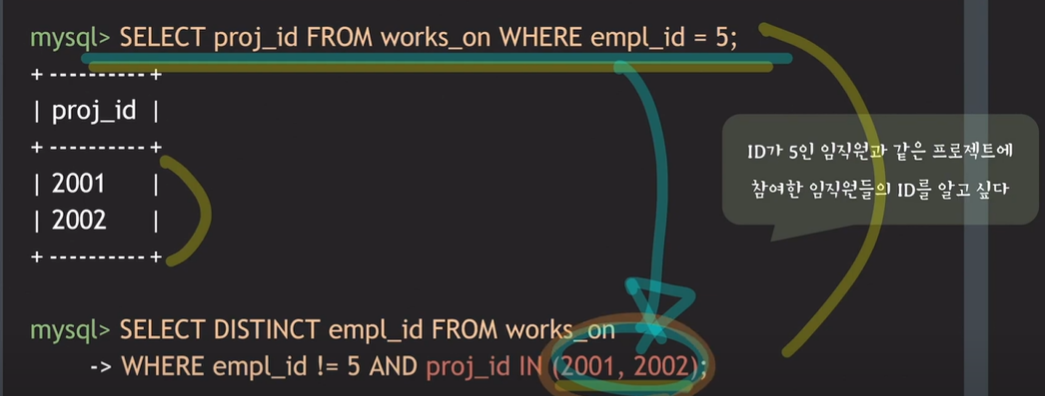
- ID가 5인 임직원과 같은 프로젝트에 참여한 임직원들의 ID를 알고 싶음

- DISTINCT : 어떤 임직원의 경우 2001, 2002 두 개의 프로젝트에 모두 참여한 경우 있을 수도 있음 -> empl_id 중복 발생할 수 있음 -> 이러한 중복을 제거하기 위함
- 위 query문은 proj_id를 두 번 써줘야하는 번거로움이 있음. ' proj_id = 2001 OR proj_id = 2002 '
- 이를 간단하게 표현하는 방법은 아래와 같다. ' proj_id IN (2001, 2002) '

- ' proj_id IN (2001, 2002) ' , ' proj_id = 2001 OR proj_id = 2002 ' 이 둘은 동일한 의미
- proj_id IN (2001, 2002) : proj_id가 2001 또는 2002, 이 두 개의 값 중에 하나라도 proj_id와 같으면 TRUE


<용어 정리>
* v IN (v1, v2, v3, ...) : v가 (v1, v2, v3, ...) 중에 하나와 값이 같다면 TURE를 return 한다
* (v1, v2, v3, ...) 는 명시적인 값들의 집합일 수도 있고 subquery의 결과(set or multiset)일 수도 있다
cf) set: 중복 허용 X, multiset: 중복 허용 O
* v NOT IN (v1, v2, v3, ...) : v가 (v1, v2, v3, ...) 의 모든 값과 값이 다르다면 TRUE를 return 한다
* unqualified attribute가 참조하는 table은 해당 attribute가 사용된 query를 포함하여 그 query의 바깥쪽으로 존재하는 모든 queries 중에 해당 attribute 이름을 가지는 가장 가까이에 있는 table을 참조한다


- ID 뿐만 아니라 이름도 알고 싶음
- works_on table에는 empl_id와 proj_id, 이 두 개의 attribute밖에 없기에 works_on table 만으로는 임직원의 이름 알 수 없음
- 임직원의 이름은 employee table에 있음, 즉 employee table 참조해야 함

- 임직원들의 ID는 구한 상태. 이 결과를 활용하여 임직원들의 이름 구하면 됨
- 이름 정보는 employee table에 있음.
- employee table을 이 결과와 연결시켜주면 됨
- 연결시켜주는 query는 다음과 같음
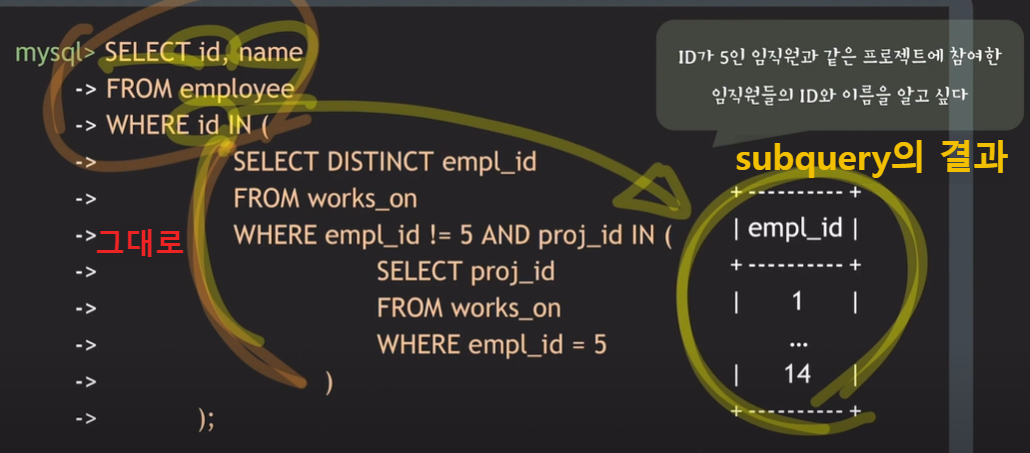
- 즉, 바로 앞에서 구한 query가 outer query에 포함되는 subquery가 됨
- subquery의 결과를 바탕으로 employee table에서 employee의 id가 결과에 있는 값들 중에 하나의 id와 같다면, 그때 그 id와 name을 가져오면 된다는 의미.

- 위와 다른 점: subquery의 위치가 WHERE절에서 FROM절로 바뀜
- FROM 위치에도 subquery가 들어갈 수 있다는 것을 보여줌
- FROM절에 2개의 table 명시
- 실제 존재하는 employee table과 subquery를 통해 나온 결과들로 이루어진 가상의 table인 DISTNCT_E
- WHERE절 바뀐 것: 위 두 개의 table을 join condition으로 묶어줌
- employee의 id와 subquery의 결과로 만들어진 가상의 table에 있는 empl_id, 이 두 개가 같은 경우에 employee의 id와 name을 반환한다는 의미.
SELECT with subquery
- ID가 7 혹은 12인 임직원이 참여한 프로젝트의 ID와 이름을 알고 싶음 (EXISTS 키워드를 사용)
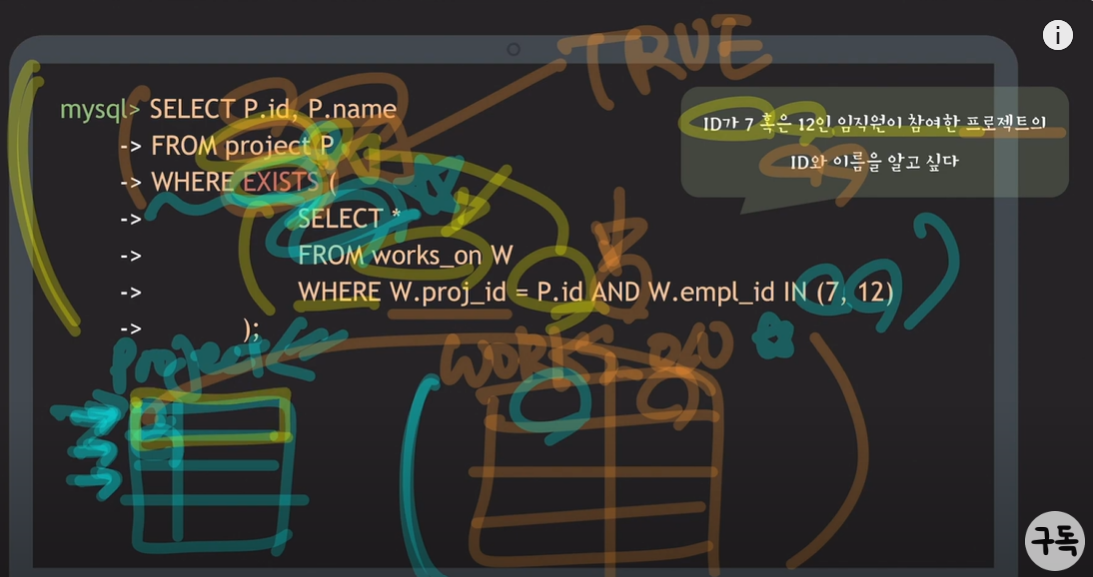
- EXISTS가 사용된 query는 먼저 outer query부터 보는 것이 편함
- project table의 tuple들을 하나씩 확인함. 하나씩 확인하면서 무언가가 존재하는 tuple을 찾음
- 그 무언가가 subquery에 명시되어 있음.
- project의 id가 works_on table에 있으면서 동시에, 프로젝트에 참여한 employee의 id가 7이거나 12인 tuple이 works_on table에 존재하면 그 project는 선택된다는 의미.
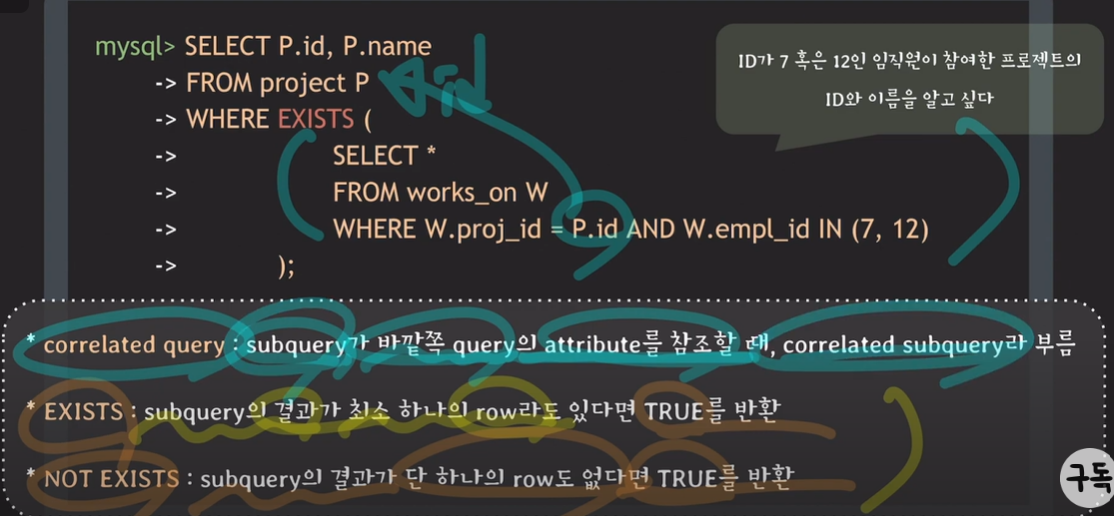
<용어 정리>
* correlated query : subquery가 바깥쪽 query의 attribute를 참조할 때, correlated subquery라 부름
* EXISTS : subquery의 결과가 최소 하나의 row라도 있다면 TRUE를 반환
* NOT EXISTS: subquery의 결과가 단 하나의 row도 없다면 TRUE를 반환
EXISTS -> IN
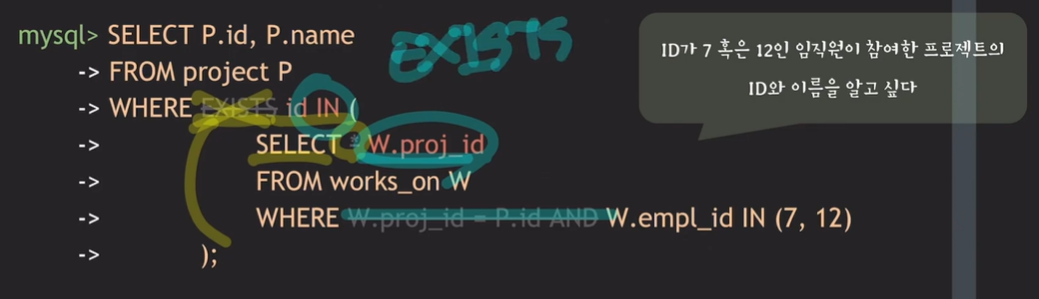
- 바깥쪽 query의 attribute를 참조하고 있던 P.id를 WHERE절로 빼주면 됨
- IN과 EXISTS는 서로 바꿔가면서 사용할 수 있음
SELECT with subquery
- 2000년대생이 없는 부서의 ID와 이름을 알고 싶음 (NOT EXISTS 사용)
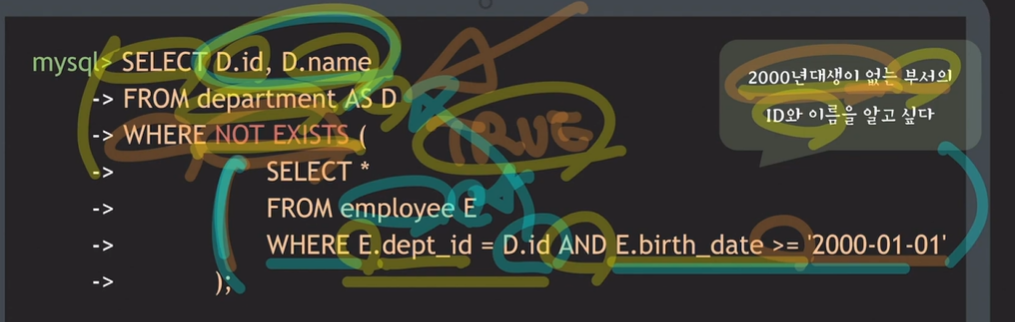
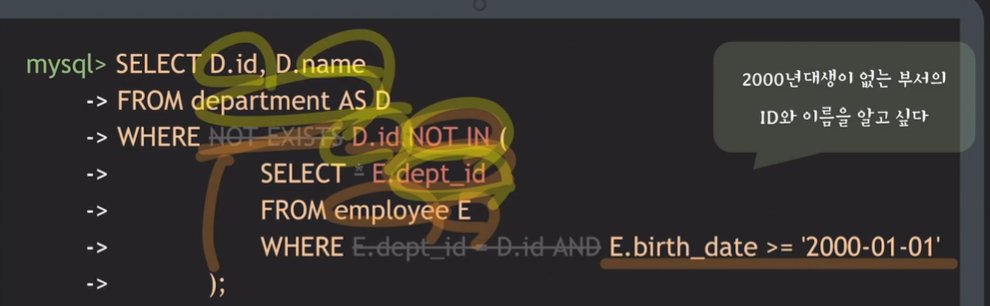
- NOT EXISTS와 NOT IN 또한 서로 바꿔가면서도 동일한 결과 낼 수 있음
SELECT with subquery
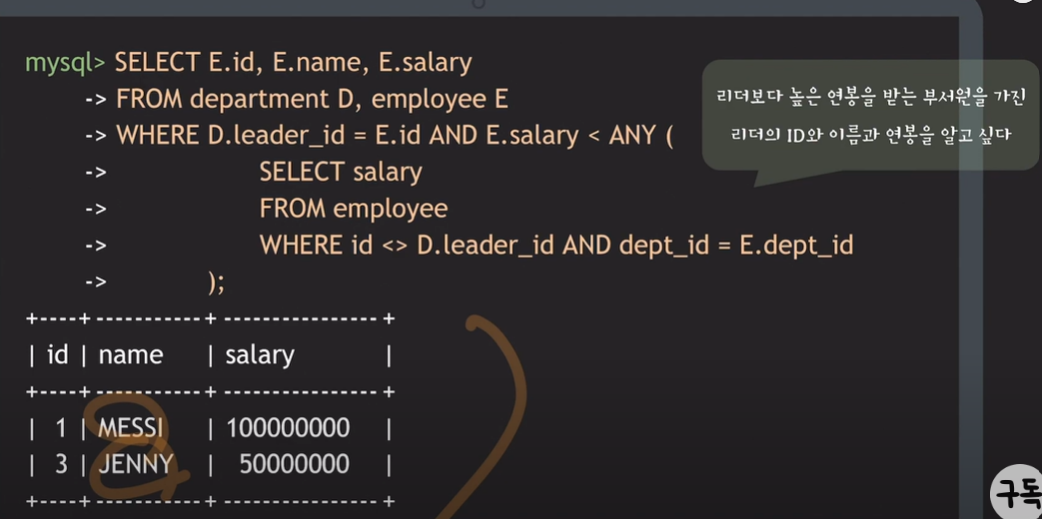
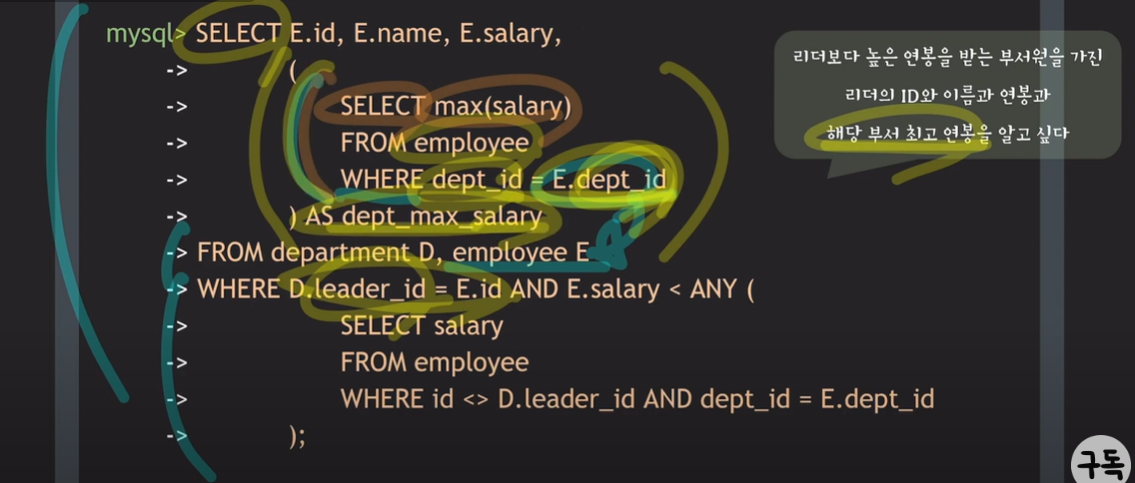
- 리더보다 높은 연봉을 받는 부서원을 가진 리더의 ID와 이름과 연봉을 알고 싶음
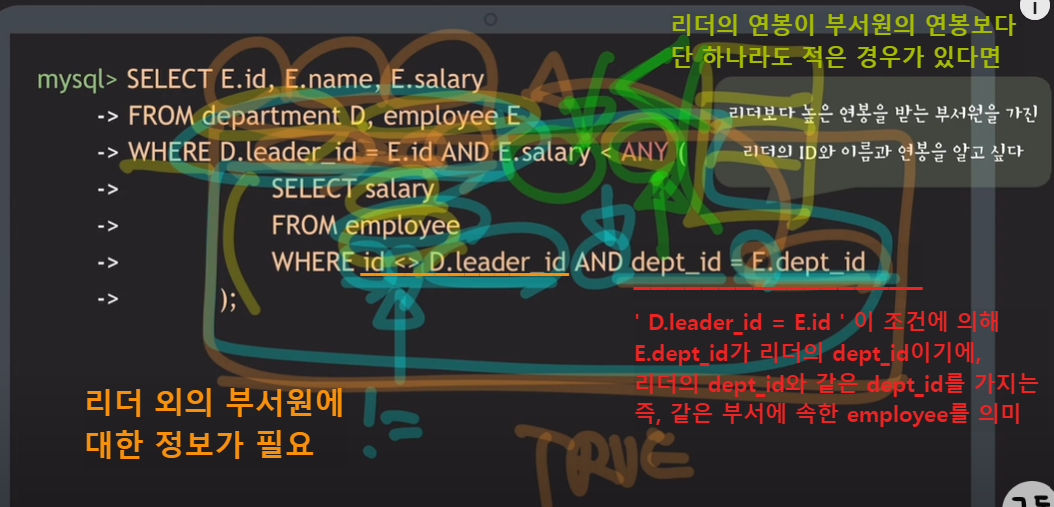
- 이름과 연봉에 대한 정보는 employee table, 리더의 ID에 대한 정보는 department table을 참조
- employee 중에 department 의 리더인 employee 만 찾아야 하기에, join condition 작성 필요 ( D.leader_id = E.id )
- 리더보다 더 많은 연봉을 받는 부서원이 부서에 존재하는지의 여부를 찾아야 함. (subquery 부분)
<용어 정리>
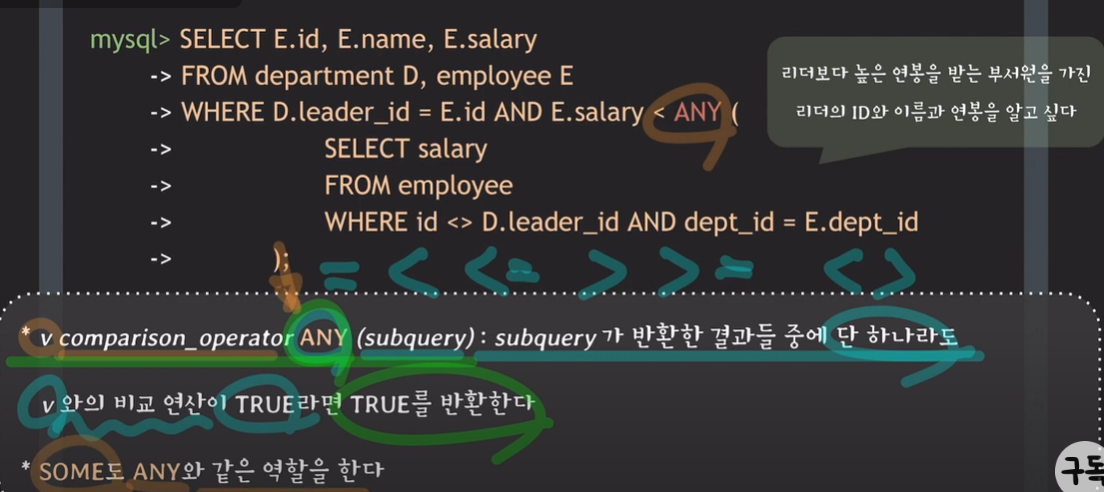
* v comparison_operator ANY (subquery) : subquery가 반환한 결과들 중에 단 하나라도 v와의 비교 연산이 TRUE라면 TRUE를 반환한다.
* SOME도 ANY와 같은 역할을 한다.

SELECT with subquery
- ID가 13인 임직원과 한번도 같은 프로젝트에 참여하지 못한 임직원들의 ID, 이름, 직군을 알고 싶음
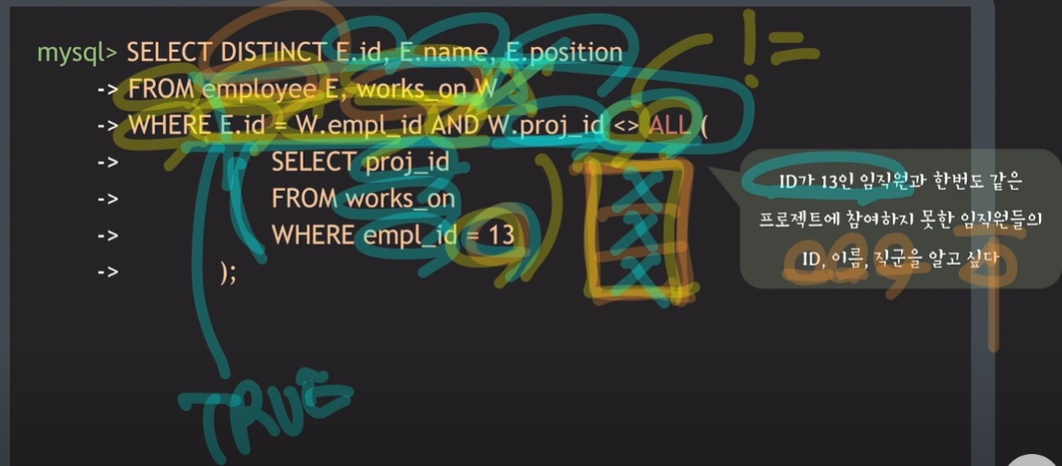
- 임직원들의 ID, 이름, 직군을 알기 위해서는 employee table이 필요함
- 이 임직원들이 어떤 프로젝트에 참여했는지 알기 위해서는 works_on table 필요함
- employee table, works_on table 이 두 개의 테이블을 연결시켜주기 위해 join condition 작성 필요( E.id = W.empl_id )
<용어 정리>
* v comparison_operator ALL(subquery) : subquery가 반환한 결과들과 v와 비교 연산이 모두 TRUE라면 TRUE 반환.
참고 사항
- 성능 비교: IN vs EXISTS
- RDBMS의 종류와 버전에 따라 다르며 최근 버전은 많은 개선이 이루어져서 IN과 EXISTS의 성능 차이 거의 없음.
- 오늘 내용은 MySQL 기준이다. 다른 RDBMS의 SQL문법은 조금씩 다를 수 있다.



